3.2 Data Handling
The learning data set was used to establish the complete analysis pipeline, i.e. preprocessing, imputation and feature selection, model evaluation and -selection and prediction method. The test data was not touched until making the final prediction, subjecting it to the complete pipeline determined on the learning data.
In accordance with recommendations in Friedman, Hastie, and Tibshirani (2001), the learning data set was further split 80/20 into training and validation sets (see Figure 2.13). The training set was used to train different models while the validation set served to tune hyperparameters. The split was performed using a stratified sampling algorithm to preserve target class frequencies based on the response indicator.
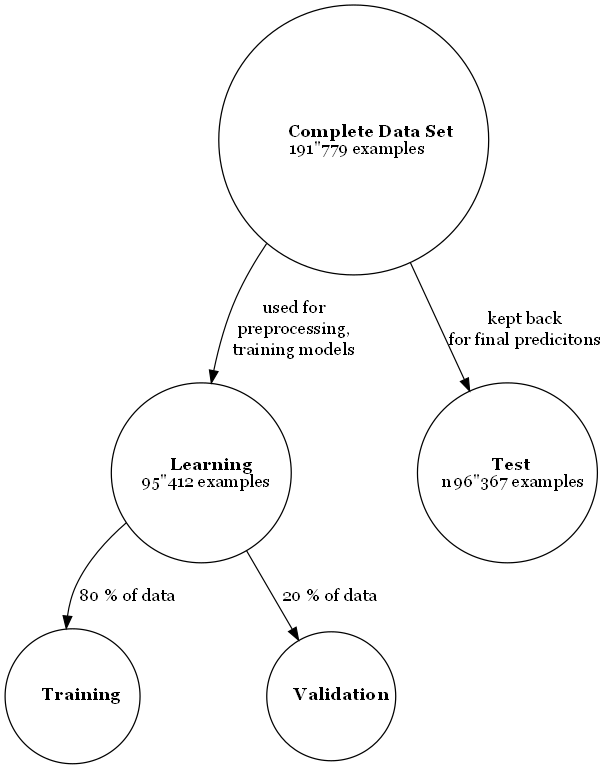
Figure 2.13: Data set use for training and predictions.